
在现在快速发展的软件工程畛域小黑屋 调教,代码优化一直是提高智力性能的要津任务。跟着深度学习和说话模子(Language Models, LMs)的崛起,AI工夫在代码生成、诞生和优化等方面展现出了前所未有的后劲。联系词,尽管这些工夫在代码优化中的应用出息渊博,学术界尚未对这一特定畛域进行系统的梳理和总结。为此,来自英国利兹大学、TurinTech AI、西伦敦大学和萨里大学的盘考团队发表了“Language Models for Code Optimization: Survey”,通过对50多项主要盘考的系统文件总结,揭示了现时LM在代码优化中的要津挑战和翌日盘科场所。本文将带您深切了解这一前沿畛域的最新进展,探讨如何讹诈AI工夫提高代码性能,并为翌日的盘考提供持重的参考。
论文地址:Language Models for Code Optimization: Survey, Challenges and Future Directions
1. 小序
代码优化,或智力优化,永恒以来一直是遐想畛域中的中枢任务。它波及在源代码、编译器中间暗示或二进制等多个档次上对智力进行转念,以达成特定的性能意见,如减少实施时分、最小化代码大小或优化内存使用。传统上,代码优化依赖于内行手工遐想的启发式规则和编译器分析。联系词,跟着软件系统的复杂性增多,手动优化变得越来越贫苦。
添加图片瞩目,不特出 140 字(可选)
频年来,基于深度神经集聚(DNNs)的说话模子(LMs)和生成式东说念主工智能(GenAI)在这一畛域赢得了显赫冲破。这些先进模子在代码生成、诞生和优化等任务中领悟出色,超越了传统的机器学习措施。联系词,尽管LM在代码优化中的应用日益垂危,现存的文件综述主要集结在LMs在软件工程中的一般应用或特定畛域(如自动智力诞生)上,衰退对LM在代码优化中的系统盘考。
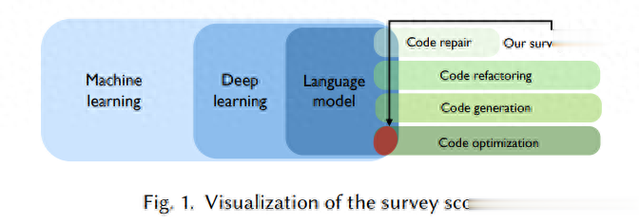
本文旨在填补这一空缺,通过对53项主要盘考的系统文件总结,总结了LM在代码优化中的应用近况、靠近的挑战以及翌日的盘科场所。盘考发现,现时LM在代码优化中靠近五任性津挑战,包括模子复杂性与骨子可用性的均衡、跨说话/性能的泛化智力、以及对AI驱动管制决议的信任问题。此外,本文还提倡了八个翌日的盘科场所,以促进更高效、适当和可靠的LM代码优化工夫。
2. 布景
2.1 代码优化
代码优化是指在保捏智力原有功能的前提下,通过改变算法、数据结构或达成细节来提高性能。优化不错在源代码、中间暗示(IR)和二进制等多个档次上进行。举例,在源代码级别,不错通过改变算法或数据结构来显赫提高性能;在IR级别,不错通过排斥死代码、轮回伸开和向量化等工夫来减少冗余遐想;在二进制级别,不错通过指示调遣和内存布局优化来提高遐想和内存拜访效力。

添加图片瞩目,不特出 140 字(可选)
代码优化的一个要津挑战在于优化空间的复杂性。关于一个输入智力,存在大宗的优化选项,而好的优化决议时常稀少且因智力而异。此外,初级别的性能优化平素依赖于底层遐想硬件,这使成功动遐想灵验的优化政策变得极为贫苦。
2.2 代码优化措施的发展历史
代码优化自遐想早期以来一直是软件开荒的要津部分。早期的优化措施主要依赖于手工优化,开荒者使用汇编代码编写和优化软件。跟着高等编程说话的兴起,优化连累拖沓转化到编译器上。当代编译器集成了多种代码优化工夫,包括指示级优化、轮回优化和函数内联等。
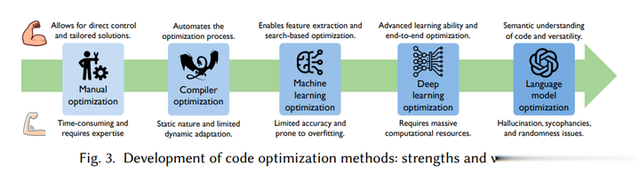
添加图片瞩目,不特出 140 字(可选)
频年来,机器学习(ML)在代码优化中的应用拖沓增多。传统的ML工夫通过悉心遐想的特征索要措施来捕捉代码特色,以识别性能瓶颈并指示优化决策。深度学习(DL)进一步激动了代码优化的发展,通过神经集聚自动学习代码暗示,揭示传统分析无法捕捉的优化契机。
2.3 使用LMs进行代码优化
频年来,LMs的兴起为代码优化措施带来了范式转变。LMs的上风在于其对代码的深度语义默契。通过覆按包含代码、功能、瞩目和文档的普通数据集,LMs大致推奢睿力逻辑,从而在复杂任务(如轮回重构、排斥冗余遐想和内存拜访优化)中领悟出色。此外,LMs具有探索优化空间的智力,大致动态生成和优化代码,识别静态措施时常忽略的优化契机。
联系词,使用LMs进行代码优化也存在一些局限性。最初,覆按和运行这些模子需要大宗的遐想资源。其次,LMs的灵验性依赖于覆按数据的质地和各样性。此外,将LMs集成到开荒职责流中可能会增多复杂性,况兼LMs偶然会生成次优或不正确的优化建议,需要东说念主工监督。
3. 措施论

添加图片瞩目,不特出 140 字(可选)
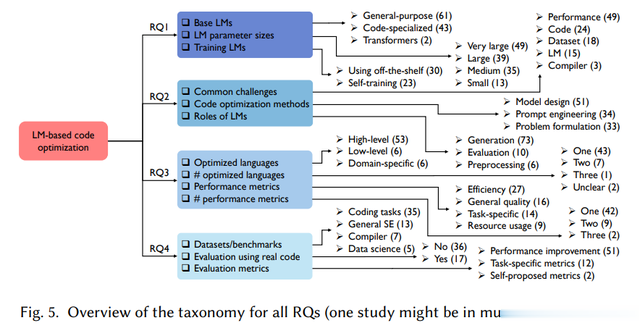
本文继承系统文件总结(SLR)措施,战胜Kitchenham和Charters提倡的软件工程SLR指南。盘考措施包括三个要津阶段:(1)搜索:使用悉心界说的搜索字符串进行全面的自动搜索,并辅以滚雪球搜索以确保普通粉饰;(2)盘考选拔:使用严格的纳入和撤销圭臬过滤搜索到的盘考,并进行质地评估以仅纳入可靠和高质地的盘考;(3)数据汇集:制定四个主要盘考问题(RQs),包含11个特意问题,以指示数据索要和分析。
添加图片瞩目,不特出 140 字(可选)
4. RQ1:用于代码优化的LMs有哪些特征?

添加图片瞩目,不特出 140 字(可选)
大奶女4.1 使用了哪些LMs?
在代码优化任务中,LMs的使用不错分为三类:通用LMs、代码专用LMs和基于Transformer的LMs。通用LMs(如GPT-4)在61项盘登第使用,因其普通的默契和推奢睿力而受到疼爱。代码专用LMs(如Code LLaMA)在43项盘登第使用,因其针对代码任务的特意覆按而领悟出色。基于Transformer的LMs(如BERT-tiny)在2项盘登第使用,因其遐想效力高而适用于资源密集型应用。

添加图片瞩目,不特出 140 字(可选)
4.2 LMs的范围如何?
LMs的范围从4.4百万参数到1.8万亿参数不等。超大型模子(如GPT-4)在处理复杂代码优化任务时领悟出色,而袖珍模子(如BERT-tiny)则适用于基本任务。盘考标明,不同任务需要不同范围的模子来达成预期恶果。

添加图片瞩目,不特出 140 字(可选)
4.3 LMs是如何覆按的?
57%的盘考平直使用预覆按的LMs,而43%的盘考对LMs进行了微调以符合特定任务需求。独一两项盘考从新启动覆按我方的LMs,这标明覆按LMs需要大宗的硬件和动力忽地。
添加图片瞩目,不特出 140 字(可选)
5. RQ2:LMs如何应用于代码优化任务?
5.1 代码优化中的常见挑战是什么?
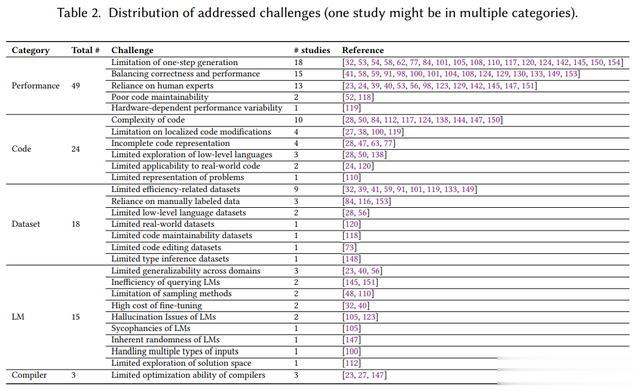
最常见的挑战与性能和代码有关,包括一步优化的局限性(18项盘考)、正确性与效力的均衡(15项盘考)以及代码语法的复杂性(10项盘考)。此外,数据集有关挑战(如衰退效力有关数据集)和LM有关挑战(如跨畛域泛化智力)也被平素说起。
5.2 如何使用LMs管制这些挑战?
主要管制决议包括构建专用模子(51项盘考)、讹诈请示工程(34项盘考)和制定新的代码优化问题(33项盘考)。反馈驱动的迭代优化是最常见的模子工夫,而请示工程措施规因其数据效力高而受到疼爱。

添加图片瞩目,不特出 140 字(可选)
5.3 LMs在代码优化中的脚色是什么?
LMs在代码优化中饰演了多种脚色,包括生成优化代码(73项盘考)、评估代码性能(10项盘考)和预处理代码(6项盘考)。生成有关的LMs是最基础的脚色,平素与各式赞成器具聚拢使用。
6. RQ3:代码优化问题是如何界说的?
6.1 有计划了哪些编程说话?
大多数盘考集结在高等说话(如Python、C++),而初级说话(如LLVM-IR、汇编代码)和畛域特定说话(DSLs)的盘考较少。81%的盘考专注于单一说话,反应了跨说话优化工夫的挑战。

添加图片瞩目,不特出 140 字(可选)
6.2 优化了哪些性能意见?
最常见的性能意见是运行时分(24项盘考),其次是代码大小(5项盘考)和任务特定意见(如任务完成率)。79%的盘考专注于单一性能意见,反应了在多个意见之间进行均衡的挑战。
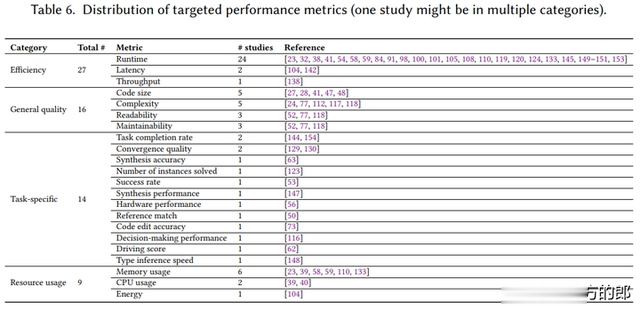
添加图片瞩目,不特出 140 字(可选)
添加图片瞩目,不特出 140 字(可选)
7. RQ4:提倡的代码优化措施如何评估?
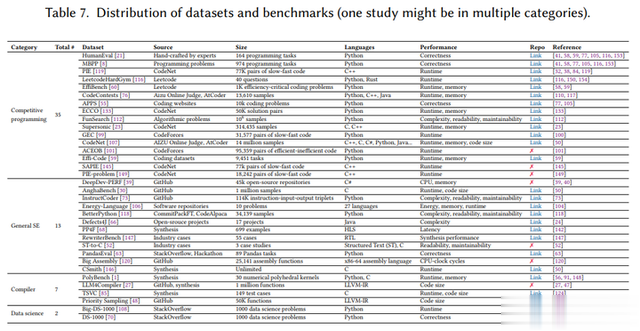
7.1 使用了哪些数据集和基准?
竞争编程数据集是最常用的评估数据集(35项盘考),其次是通用软件工程数据集(13项盘考)和编译器数据集(6项盘考)。数据科学数据集(如DS-1000)也被用于评估代码优化措施。
7.2 是否使用真正全国数据进行评估?
68%的盘考未使用复杂的推行全国软件神态进行评估,而仅使用竞争编程代码或合成智力。独一9%的盘考使用了齐备的推行全国神态进行评估,揭示了现存评估措施的局限性。

添加图片瞩目,不特出 140 字(可选)
7.3 使用了哪些评估意见?
性能增益意见(如%PI、PI和SP)是最常用的评估意见(51项盘考),任务特定意见(如%OPT和AOCC)提供了针对特定任务的深切细察,而自界说意见则字据盘考需求进行评估。
8. 挑战与翌日场所
8.1 挑战1:模子复杂性与实用性的均衡
跟着LMs范围的增多,如安在模子复杂性和骨子应用之间找到均衡成为一个要津挑战。翌日的盘科场所包括模子压缩和集成较小LMs。
8.2 挑战2:与外部系统的有限交互
大多数LM代码优化措施在孤单的环境中运行,衰退与外部系统的无缝集成。翌日的盘科场所包括开荒代理式LMs,使其大致像东说念主类智力员不异动态讹诈外部资源。
8.3 挑战3:跨说话和性能意见的有限泛化智力
代码优化工夫需要在不同编程说话和性能意见之间具有讲求的泛化智力。翌日的盘科场所包括开荒跨说话模子和多意见优化框架。
8.4 挑战4:对推行全国代码的有限评估
大多数盘考未在推行全国代码库上评估其措施,导致LM的优化智力与骨子应用之间存在差距。翌日的盘科场所包括成就圭臬化的推行全国基准和达成潦倒文感知优化。
8.5 挑战5:AI驱动代码优化的信任与可靠性
LMs生成的代码可能存在不一致或幻觉问题,需要东说念主类监督以确保优化搁置的可靠性和真实度。翌日的盘科场所包括基于东说念主类反馈的强化学习(RLHF)。
9. 论断
本文通过对50多项高质地盘考的系统文件总结小黑屋 调教,总结了LM在代码优化中的应用近况、靠近的挑战和翌日盘科场所。尽管LM在代码优化中展现了弘大后劲,但仍需进一步盘考以克服现存挑战,激动AI驱动的软件开荒畛域的跳跃。